Classification - HELOC Credit Risk
Predicting credit risk for Home Equity Line of Credit applications using the FICO HELOC dataset.
Dataset Source:
FICO HELOC Dataset
Problem Type: Classification
Target Variable: RiskPerformance - Whether
applicant will pay as negotiated (Good/Bad) Use Case: Credit risk assessment for
financial institutions to identify borrowers at risk of defaulting
Package Imports
Install and import relevant packages
Data Loading and Exploration
Load the HELOC dataset and explore its structure
Where the defition of each of the fields are below:
| Variable Names | Description |
|---|---|
| RiskPerformance | Paid as negotiated flag (12-36 Months). String of Good and Bad |
| ExternalRiskEstimate | Consolidated version of risk markers |
| MSinceOldestTradeOpen | Months Since Oldest Trade Open |
| MSinceMostRecentTradeOpen | Months Since Most Recent Trade Open |
| AverageMInFile | Average Months in File |
| NumSatisfactoryTrades | Number of Satisfactory Trades |
| NumTrades60Ever2DerogPubRec | Number of Trades 60+ Ever |
| NumTrades90Ever2DerogPubRec | Number of Trades 90+ Ever |
| PercentTradesNeverDelq | Percent of Trades Never Delinquent |
| MSinceMostRecentDelq | Months Since Most Recent Delinquency |
| MaxDelq2PublicRecLast12M | Max Delinquency/Public Records in the Last 12 Months. See tab 'MaxDelq' for each category |
| MaxDelqEver | Max Delinquency Ever. See tab 'MaxDelq' for each category |
| NumTotalTrades | Number of Total Trades (total number of credit accounts) |
| NumTradesOpeninLast12M | Number of Trades Open in Last 12 Months |
| PercentInstallTrades | Percent of Installment Trades |
| MSinceMostRecentInqexcl7days | Months Since Most Recent Inquiry excluding the last 7 days |
| NumInqLast6M | Number of Inquiries in the Last 6 Months |
| NumInqLast6Mexcl7days | Number of Inquiries in the Last 6 Months excluding the last 7 days. Excluding the last 7 days removes inquiries that are likely due to price comparison shopping. |
| NetFractionRevolvingBurden | This is the revolving balance divided by the credit limit |
| NetFractionInstallBurden | This is the installment balance divided by the original loan amount |
| NumRevolvingTradesWBalance | Number of Revolving Trades with Balance |
| NumInstallTradesWBalance | Number of Installment Trades with Balance |
| NumBank2NatlTradesWHighUtilization | Number of Bank/National Trades with high utilization ratio |
| PercentTradesWBalance | Percent of Trades with Balance |
1. Data Preprocessing
Prepare features and target variable
Create Train/Test Split
2. Model Optimization
The XParamOptimiser fine-tunes the hyperparameters of our model to achieve optimal performance.
3. Model Training
Train the XClassifier with optimized parameters.
4. Model Interpretability and Explainability
Generate insights into the model's decision-making process and understand feature importance.
Analysing Feature Importances and Contributions
Click on the bars to see the importances and contributions of each variable.
Feature Importances
The relative significance of each feature (or input variable) in making predictions. It indicates how much each feature contributes to the model’s predictions, with higher values implying greater influence.
Feature Significance
The effect of each feature on individual predictions. For instance, in this model, feature contributions would show how each feature (like the net fraction of trades revolving burden) affects the predicted risk estimate for a particular applicant.
5. Model Persistence
Save the model to Xplainable Cloud for collaboration and deployment.
In this step, we first create a unique identifier for our HELOC risk prediction model using client.create_model_id. This identifier, referred to as model_id, represents the newly created model that predicts the likelihood of applicants defaulting on their line of credit. After creating this model identifier, we generate a specific version of the model using client.create_model_version, passing in our training data. The resulting version_id represents this particular iteration of our model, allowing us to track and manage different versions systematically.
Xplainable Cloud Setup
Preprocessor Persistence
Save the preprocessing specification to Xplainable Cloud alongside the model.
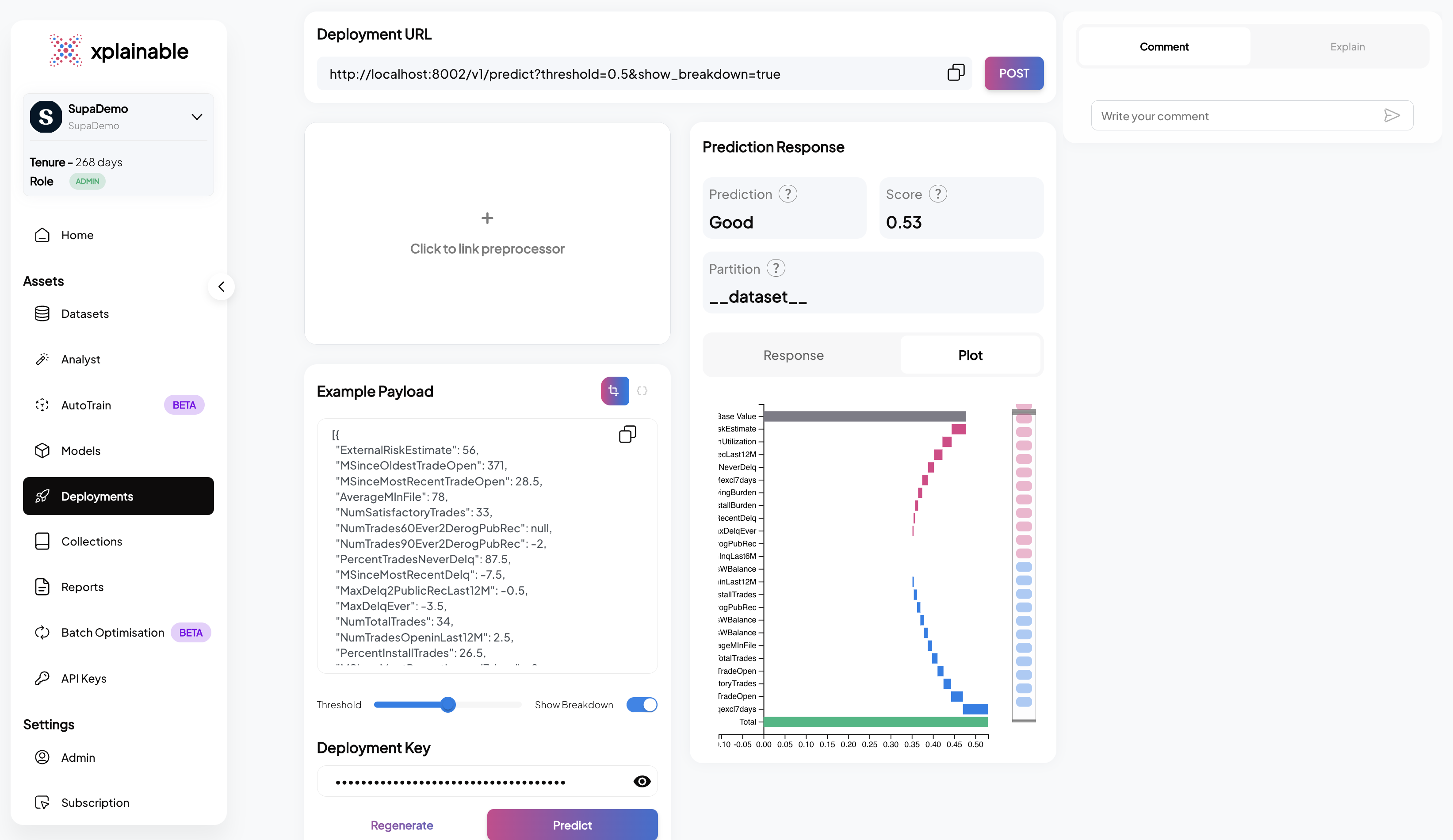
6. Model Deployment
Deploy the model for real-time predictions.
The code block illustrates the deployment of our credit risk prediction model using the
client.deployments.deploy function. The deployment process involves specifying the
unique model_version_id that we obtained in the previous steps. This step effectively
activates the model's endpoint, allowing it to receive and process prediction requests.
The deployment response confirms the successful deployment with a deployment_id and
other relevant information.
print(f"Deployment ID: {deployment_id}")
- Activating the Deployment: The model deployment is activated using
client.activate_deployment, which changes the deployment status to active, allowing it to accept prediction requests.
- Making a Prediction Request: A POST request is made to the model's prediction endpoint with the example payload. The model processes the input data and returns a prediction response, which includes the predicted class (e.g., 'No' for no churn) and the prediction probabilities for each class.